Using the collection¶
Users interested in analyzing the KGTorrent database should download it from its Zenodo repository; it is stored as a compressed archive named KGT_dataset.tar.bz2. The dataset can be analyzed as a whole, although we believe that the most interesting use case is to leverage the companion database to select a subset of notebooks based on specific research criteria. To this aim, along with the dataset, one should download the compressed archive containing the dump of the MySQL database (named KGTorrent_dump_10-2020.sql.tar.bz2), uncompress it and import it into a local MySQL installation.
You can use the Linux tar command to uncompress both archives:
tar -xf KGT_dataset.tar.bz2 -C /path/to/local/dataset/folder
tar -xf KGTorrent_dump_10-2020.sql.tar.bz2
Then, import the MySQL dump in your local MySQL installation. To perform this step, you can follow this guide.
Once the database has been correctly imported, you can query it to select a subset of notebooks based on specific criteria. The Jupyter notebooks in KGTorrent are saved with filenames following this pattern: UserName_CurrentUrlSlug, where UserName is a field of the Users table, while CurrentUrlSlug is a field of the Kernels table. Therefore, by including such pattern in the SELECT statement of an SQL query, the result will comprise a column listing the names of the selected Jupyter notebooks from the dataset.
In the following example, I select the filenames of all Python Jupyter notebooks that have been awarded a gold medal in Kaggle:
SELECT CONCAT(u.UserName, '_', k.CurrentUrlSlug, '.ipynb') FilteredNotebookNames
FROM ((kernels k JOIN users u ON k.AuthorUserId = u.Id)
JOIN kernelversions kv ON k.CurrentKernelVersionId = kv.Id)
JOIN kernellanguages kl ON kv.ScriptLanguageId = kl.Id
WHERE kl.name LIKE 'IPython Notebook HTML'
AND k.Medal = 1;
Note that IPython Notebook HTML is the language name used in Meta Kaggle to identify Jupyter notebooks written in Python.
In MySQL, if you want to save the results of the query above to a .csv file, you can extend it as follows:
SELECT CONCAT(u.UserName, '_', k.CurrentUrlSlug, '.ipynb') FilteredNotebookNames
FROM ((kernels k JOIN users u ON k.AuthorUserId = u.Id)
JOIN kernelversions kv ON k.CurrentKernelVersionId = kv.Id)
JOIN kernellanguages kl ON kv.ScriptLanguageId = kl.Id
WHERE kl.name LIKE 'IPython Notebook HTML'
AND k.Medal = 1
INTO OUTFILE '/var/lib/mysql-files/query_result.csv'
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
In the GitHub repository (at docs/imgs/KGTorrent_logical_schema.png) as well as in the Zenodo repository containing the dataset, we share the logical schema underlying the KGTorrent database. We built this schema by reverse engineering a relationa model from Meta Kaggle data.
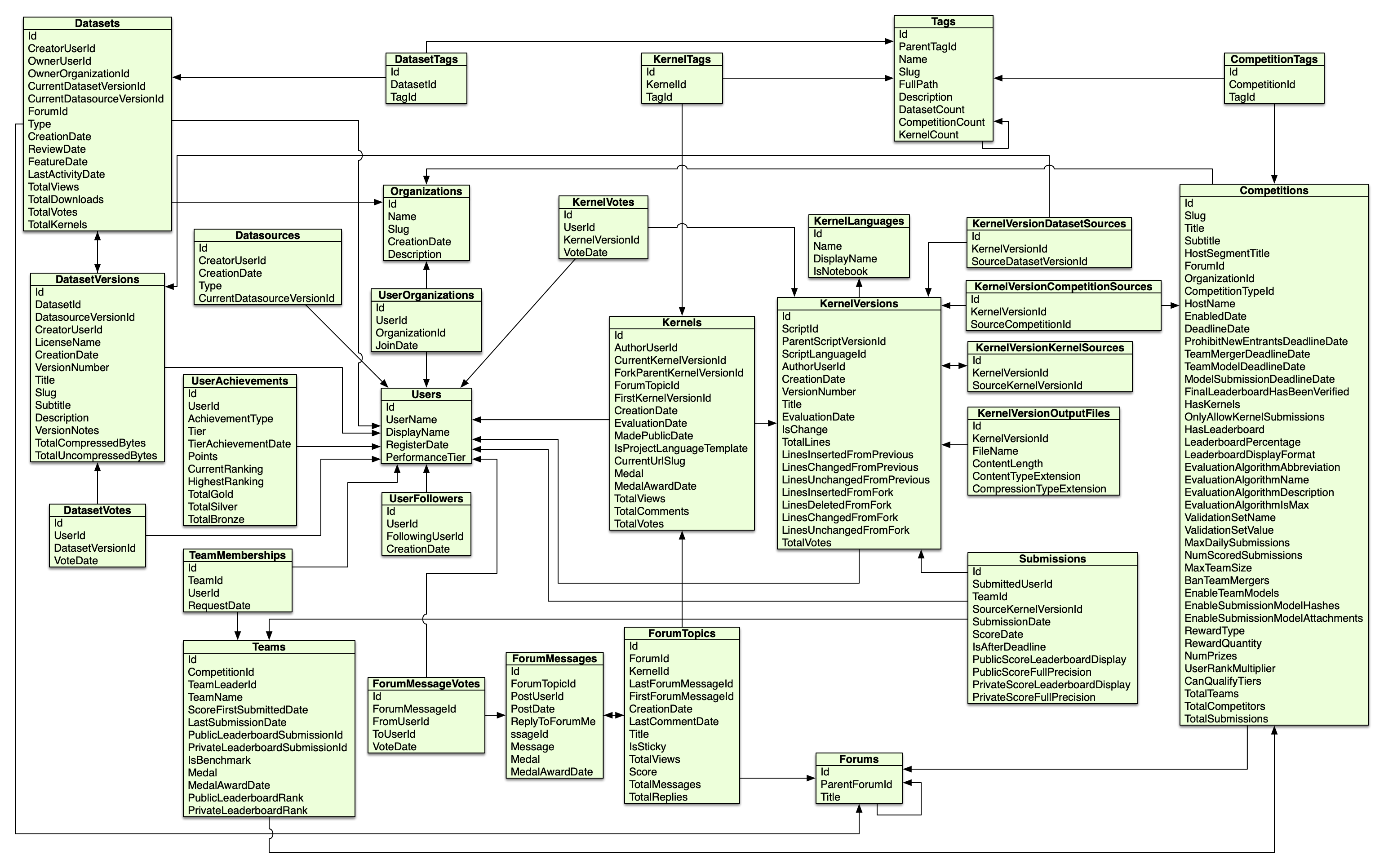
All the most relevant relationships among the db tables are explicitly represented in the schema. However, we decided to omit some of them to ensure a good readability of the image.